背景概述
这里所说的数据持久化是针对浏览器而言,也可简称为浏览器缓存。
浏览器缓存是指浏览器端在本地保存数据进行快速读取以避免重复资源请求。
现代浏览器主要有9种缓存机制:Http文件缓存、LocalStorage、SessionStorage、indexDB、Web SQL、Cookie、CacheStorage、Application Cache、Flash缓存 - 《现代前端技术解析》
《现代前端技术解析》对应浏览器: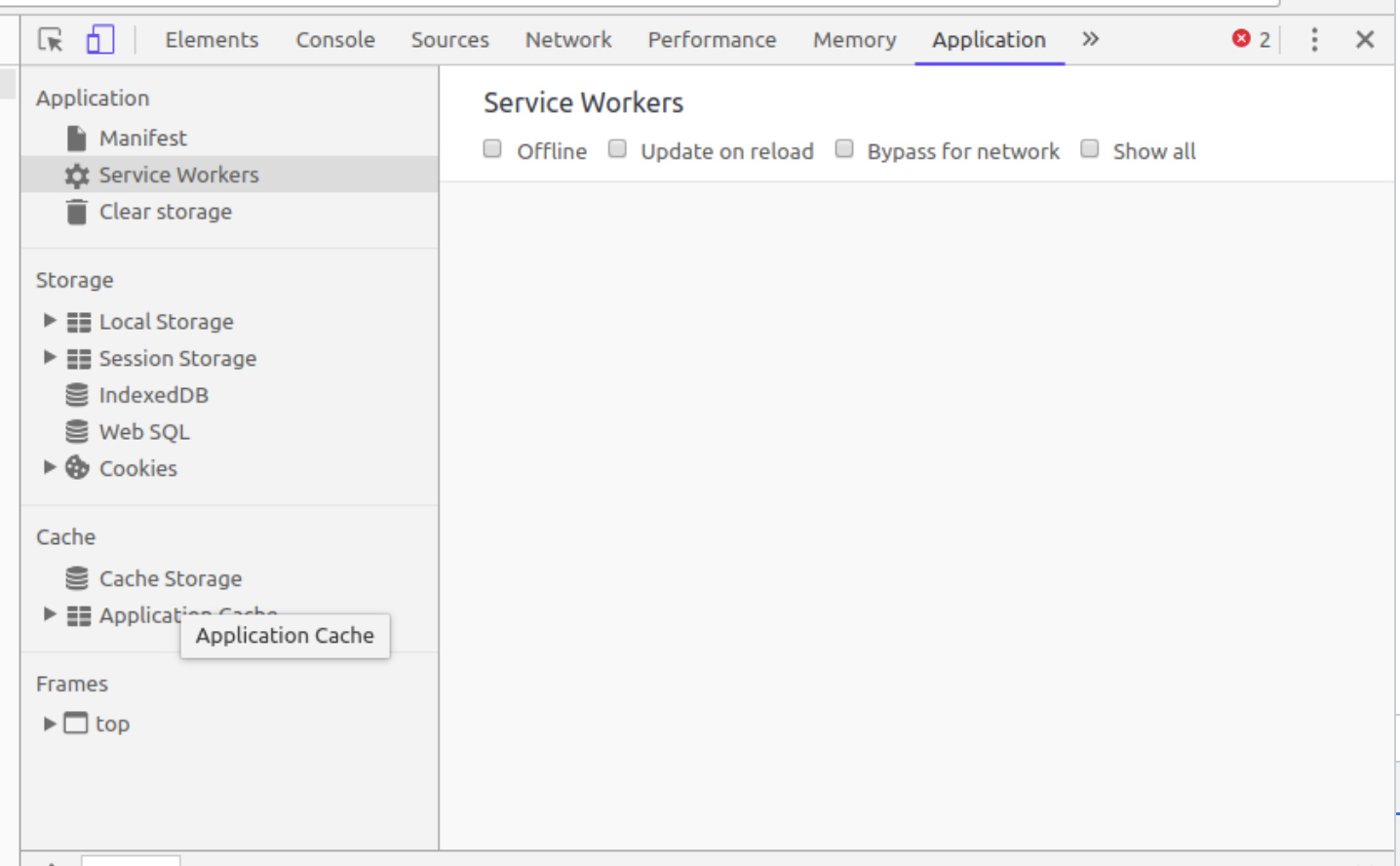
新浏览器: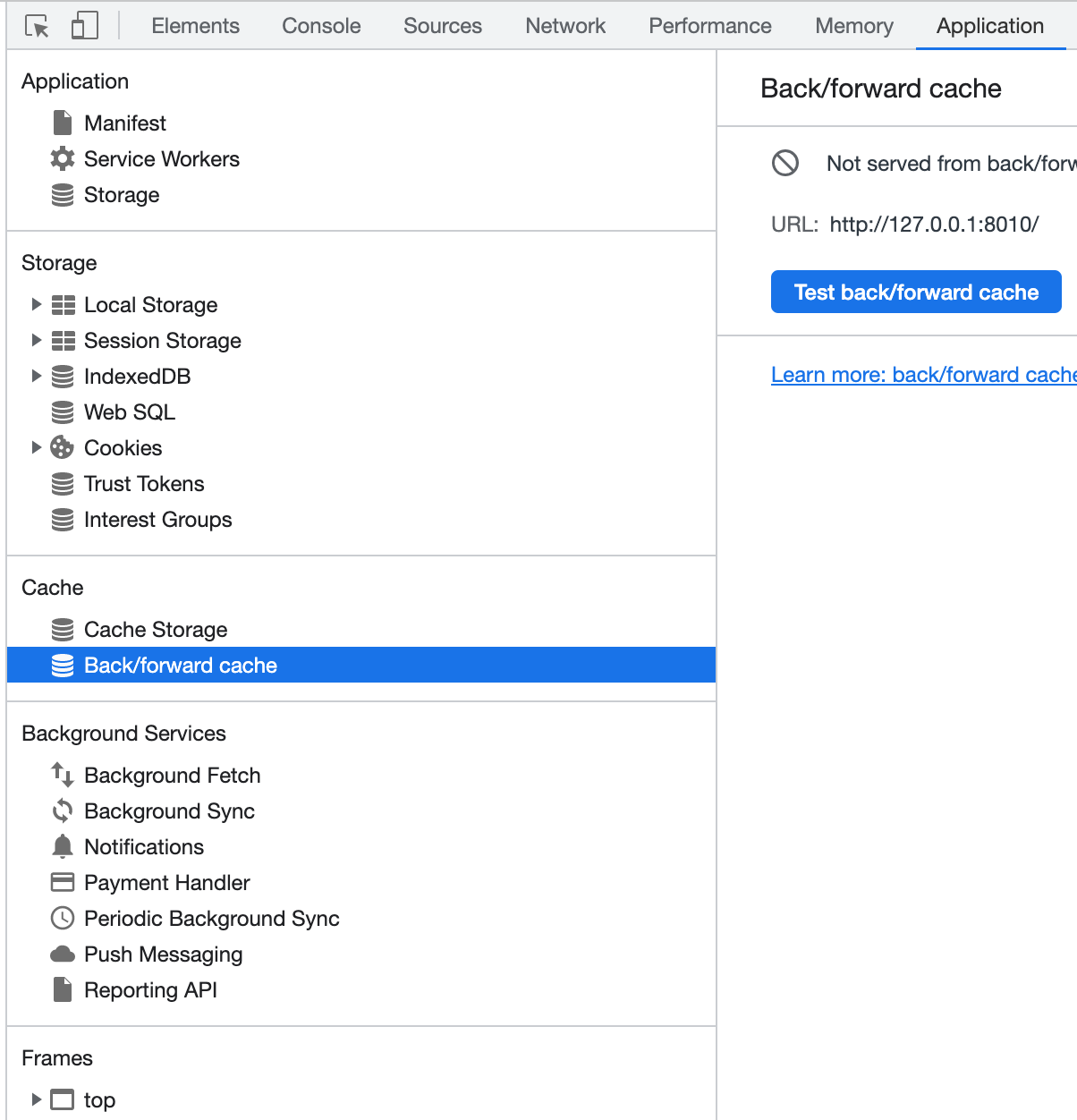
最新版Chrome浏览器面板中 Application Cache 没有了,见下图解释,感兴趣的可自行查阅😊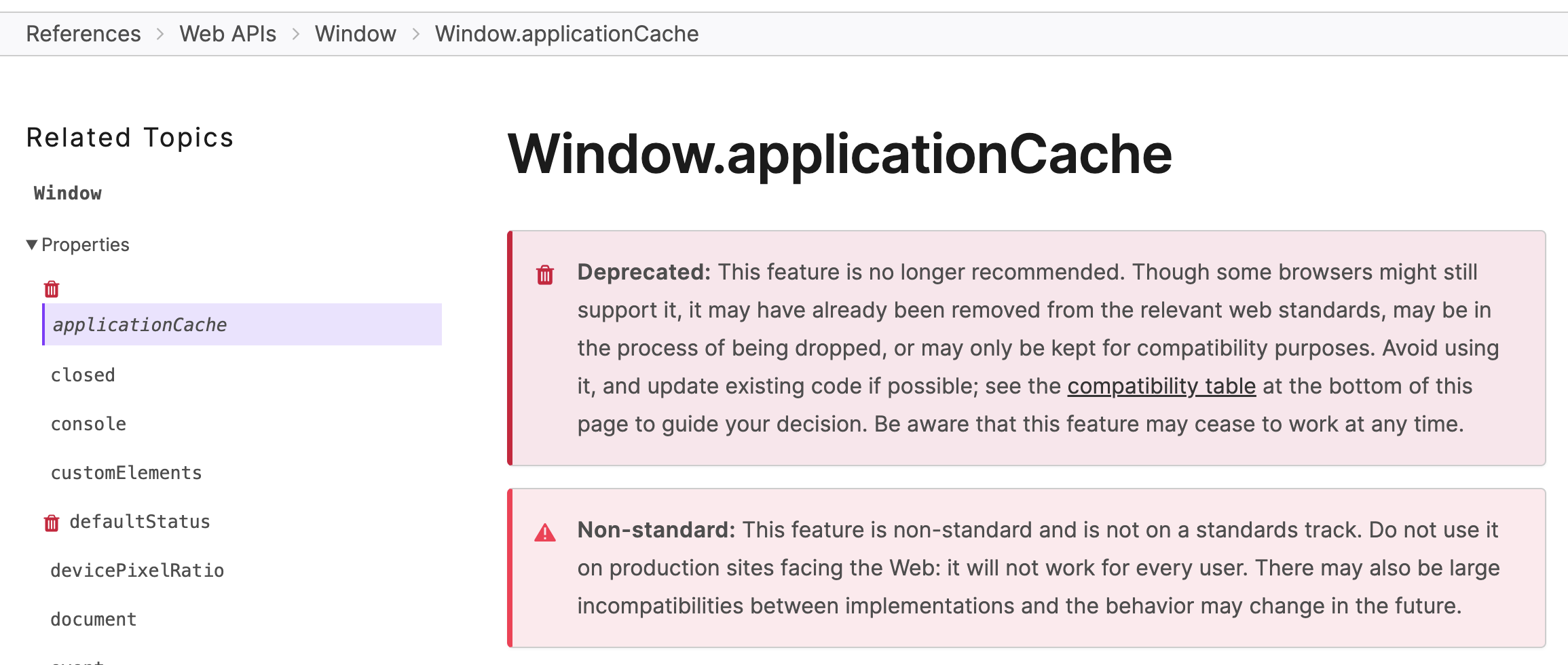
诉求&哪种方式?
诉求
地图map api请求大量地理位置json,当然每次访问页面时请求也可,但这个不怎么变其实是没必要的,缓存在各个客户端本地即可,定期清除再获取新json存储。减少请求,减少费用,本地读取,这样不是大家都开心。
哪种方式
缓存资料上会建议用以下:
- For the network resources necessary to load your app and file-based content, use the Cache Storage API
(part of service workers). - For other data, use IndexedDB (with a promises wrapper).
那为啥不用LocalStorage、SessionStorage?可以参考 storage-for-the-web 或 阅读《现代前端技术解析》第1.2.3章节。
IndexDB
是什么?
indexedDB是可以在浏览器端使用的本地数据库
可以存储大量数据,提供接口来查询,还可以建立索引,这些都是其他存储方案 Cookie 或者 LocalStorage 无法提供的能力
从数据库类型来看,IndexedDB 是一个非关系型数据库(不支持通过 SQL 语句操作)。
主要概念
IndexedDB 是一个比较复杂的 API 组合,包括以下这些( IDB 指当前操作的数据库实例 ):
- 数据库:IDBDatabase 对象
- 数据库是所有相关数据的基本容器。在同源策略( 协议 + 域名 + 端口 )的前提下,每个域名下可以新建任意多的数据库。IndexedDB 中有版本概念,这就规定了同一时刻下只有一个版本的数据库存在。
- 仓库对象: IDBObjectStore 对象
- 对象仓库 ObjectStore 在 IndexedDB 中对应的是 MYSQL 中的表 Table。
- 对象仓库中记录的是若干条数据,数据只有主键和数据体两个部分,主键不能重复,可以为自增的整数编号或者数据中指定的一个属性。数据体可以是任意数据类型,不限于对象。
- 索引:IDBIndex 对象
- 为不同的属性建立索引可以加快数据的检索。
- 事务:IDBTransaction 对象
- 数据的 CURD (增删查改) 都要通过事务来完成。
- 操作请求:IDBRequest 对象
- 指针:IDBCursor 对象
- 主键:IDBKeyRange 对象
对比mysql
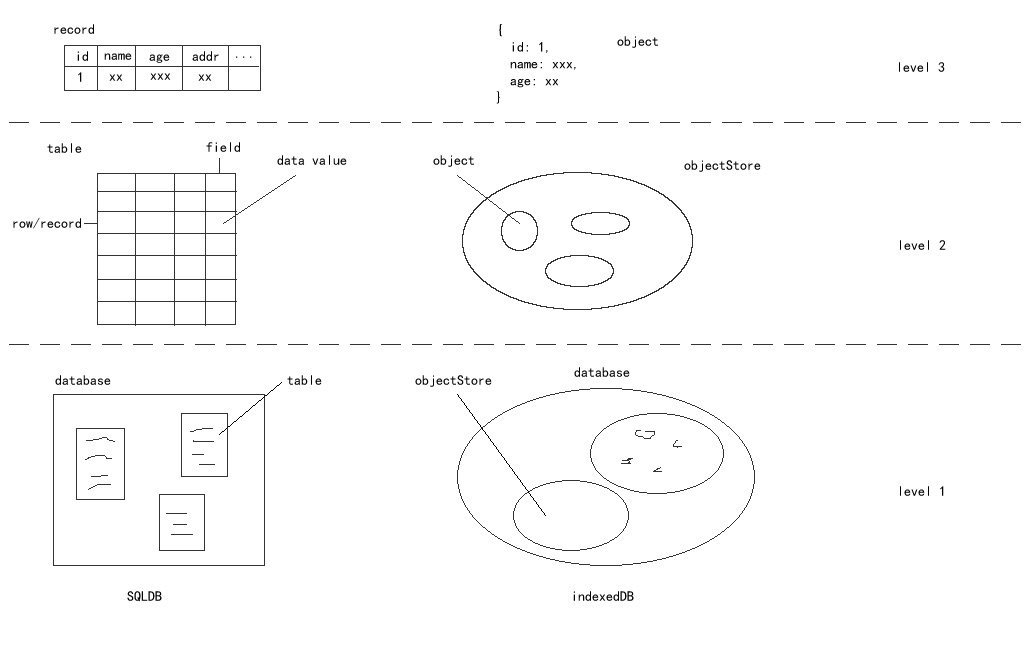
实操特性总结
- key-value 的储存形式,透过索引功能来高效率搜寻资料
- 同源政策 same-origin policy:只能取用同网域下的资料
- Async API : 提供异步 api,单线程的应用下取用资源时就不会有 block the main thread 的情况造成使用者体验不佳
- transaction : 能够确保大量写入资源时的完整性,如果有单一资源写入失败可全数 rollback
设备兼容性
兼容性查询:https://caniuse.com/indexeddb
存储容量
单一资源库项目的容量/大小并没有任何限制,但是各个 IndexedDB资源库的容量就有限制,且根据各浏览器其限制会不同。
Chromeallows the browser to use up to 60% of total disk space. You can use the StorageManager API to determine the maximum quota available. Other Chromium-based browsers may allow the browser to use more storage.Internet Explorer 10 and latercan store up to 250MB and will prompt the user when more than 10MB has been used.Firefoxallows an origin to use up to 2GB. You can use the StorageManager API to determine how much space is still available.Safari (both desktop and mobile)appears to allow up to 1GB. When the limit is reached, Safari will prompt the user, increasing the limit in 200MB increments. I was unable to find any official documentation on this.
可参考 storage-for-the-web存储资源键(Key)
- data type: string, date, float和 array
- 必须是能排序的值(无法处理多国语言字串排序)
- 资源存储三种方式产生资源存储键: 键产生器 (key generator)、键路径 (key path) 以及指定值。
- 键产生器 (key generator): 用产生器自动产生键
- 键路径 (key path):空字串或是javascript identifier(包含用 “.” 分隔符号的名称)且路径不能有空白
操作流程
打开数据库
IndexedDB使用第一步:打开数据库。
方法:indexedDB.open()
var request = window.indexedDB.open(databaseName, version);
这个方法接受两个参数,第一个参数是字符串,表示数据库的名字。如果指定的数据库不存在,就会新建数据库。第二个参数是整数,表示数据库的版本。如果省略,打开已有数据库时,默认为当前版本;新建数据库时,默认为1。
indexedDB.open()方法返回一个 IDBRequest 对象。这个对象通过三种事件error、success、upgradeneeded,处理打开数据库的操作结果。
(1)error 事件
error事件表示打开数据库失败。
request.onerror = function (event) {
console.log('数据库打开报错');
};
(2)success 事件
success事件表示成功打开数据库。
var db;
request.onsuccess = function (event) {
db = request.result;
console.log('数据库打开成功');
};
这时,通过request对象的result属性拿到数据库对象。
(3)upgradeneeded 事件
如果指定的版本号,大于数据库的实际版本号,就会发生数据库升级事件upgradeneeded。
var db;
request.onupgradeneeded = function (event) {
db = event.target.result;
}
这时通过事件对象的target.result属性,拿到数据库实例。
新建数据库
新建数据库与打开数据库是同一个操作。如果指定的数据库不存在,就会新建。不同之处在于,后续的操作主要在upgradeneeded事件的监听函数里面完成,因为这时版本从无到有,所以会触发这个事件。
通常,新建数据库以后,第一件事是新建对象仓库(即新建表)。
request.onupgradeneeded = function(event) {
db = event.target.result;
var objectStore = db.createObjectStore('person', { keyPath: 'id' });
}
上面代码中,数据库新建成功以后,新增一张叫做person的表格,主键是id。
先判断一下,这张表格是否存在,如果不存在再新建。
request.onupgradeneeded = function (event) {
db = event.target.result;
var objectStore;
if (!db.objectStoreNames.contains('person')) {
objectStore = db.createObjectStore('person', { keyPath: 'id' });
}
}
主键(key)是默认建立索引的属性。比如,数据记录是{ id: 1, name: ‘张三’ },那么id属性可以作为主键。主键也可以指定为下一层对象的属性,比如{ foo: { bar: ‘baz’ } }的foo.bar也可以指定为主键。
如果数据记录里面没有合适作为主键的属性,那么可以让 IndexedDB 自动生成主键。
var objectStore = db.createObjectStore(
'person',
{ autoIncrement: true }
);
上面代码中,指定主键为一个递增的整数。
新建对象仓库以后,下一步可以新建索引。
request.onupgradeneeded = function(event) {
db = event.target.result;
var objectStore = db.createObjectStore('person', { keyPath: 'id' });
objectStore.createIndex('name', 'name', { unique: false });
objectStore.createIndex('email', 'email', { unique: true });
}
上面代码中,IDBObject.createIndex()的三个参数分别为索引名称、索引所在的属性、配置对象(说明该属性是否包含重复的值)。
新增数据
新增数据指的是向对象仓库写入数据记录。这需要通过事务完成。
function add() {
var request = db.transaction(['person'], 'readwrite')
.objectStore('person')
.add({ id: 1, name: '张三', age: 24, email: 'zhangsan@example.com' });
request.onsuccess = function (event) {
console.log('数据写入成功');
};
request.onerror = function (event) {
console.log('数据写入失败');
}
}
add();
上面代码中,写入数据需要新建一个事务。新建时必须指定表格名称和操作模式(”只读”或”读写”)。新建事务以后,通过IDBTransaction.objectStore(name)方法,拿到 IDBObjectStore 对象,再通过表格对象的add()方法,向表格写入一条记录。
写入操作是一个异步操作,通过监听连接对象的success事件和error事件,了解是否写入成功。
读取数据
读取数据也是通过事务完成。
function read() {
var transaction = db.transaction(['person']);
var objectStore = transaction.objectStore('person');
var request = objectStore.get(1);
request.onerror = function(event) {
console.log('事务失败');
};
request.onsuccess = function( event) {
if (request.result) {
console.log('Name: ' + request.result.name);
console.log('Age: ' + request.result.age);
console.log('Email: ' + request.result.email);
} else {
console.log('未获得数据记录');
}
};
}
read();
上面代码中,objectStore.get()方法用于读取数据,参数是主键的值。
遍历数据
遍历数据表格的所有记录,要使用指针对象 IDBCursor。
function readAll() {
var objectStore = db.transaction('person').objectStore('person');
objectStore.openCursor().onsuccess = function (event) {
var cursor = event.target.result;
if (cursor) {
console.log('Id: ' + cursor.key);
console.log('Name: ' + cursor.value.name);
console.log('Age: ' + cursor.value.age);
console.log('Email: ' + cursor.value.email);
cursor.continue();
} else {
console.log('没有更多数据了!');
}
};
}
readAll();
上面代码中,新建指针对象的openCursor()方法是一个异步操作,所以要监听success事件。
更新数据
方法:IDBObject.put()
function update() {
var request = db.transaction(['person'], 'readwrite')
.objectStore('person')
.put({ id: 1, name: '李四', age: 35, email: 'lisi@example.com' });
request.onsuccess = function (event) {
console.log('数据更新成功');
};
request.onerror = function (event) {
console.log('数据更新失败');
}
}
update();
上面代码中,put()方法自动更新了主键为1的记录。
删除数据
方法:IDBObjectStore.delete()
function remove() {
var request = db.transaction(['person'], 'readwrite')
.objectStore('person')
.delete(1);
request.onsuccess = function (event) {
console.log('数据删除成功');
};
}
remove();
使用索引
索引的意义在于,可以让你搜索任意字段,也就是说从任意字段拿到数据记录。如果不建立索引,默认只能搜索主键(即从主键取值)。
假定新建表格的时候,对name字段建立了索引。
objectStore.createIndex('name', 'name', { unique: false });
现在,就可以从name找到对应的数据记录了。
var transaction = db.transaction(['person'], 'readonly');
var store = transaction.objectStore('person');
var index = store.index('name');
var request = index.get('李四');
request.onsuccess = function (e) {
var result = e.target.result;
if (result) {
// ...
} else {
// ...
}
}
idb
idb
一个很小的(〜1.05k)库,主要反映了索引的DB API,对可用性有了很大的改进。
错误处理QuotaExceededError
使用者浏览器的内存不足时会丢出 QuotaExceededError (DOMException) 的错误, 务必记得handle error避免使用者体验不好,并依照各自逻辑进行错误处理。
eg. 当transaction时出现错误会调用callback.onabort
// 以上范例加上error handler
const transaction = db.transaction(['person'], 'readwrite');
transaction.onabort = function(event) {
const error = event.target.error; // DOMException
if (error.name == 'QuotaExceededError') {
// Fallback code goes here
}
};

浏览器清空indexDB
Web storage is categorized into two buckets, “Best Effort” and “Persistent”
indexedDB 属于”Best Effort”(非常久性) 当浏览器空间不足时会开始清除非持久性资料 也就是eviction policy
- Chromium-based browsers: 当浏览器空间不足时,会开始从最少使用的data清除直到空间不再超出限制。
- Internet Explorer 10+: 没有清除机制,但无法再写入新资料。
- Firefox: 当硬盘空间不足时,会开始从最少使用的data清除直到空间不再超出限制。
- Safari: 以前没有清除机制, 但现行有实施7日机制(当使用者七日没有使用safari时,将会清空资料)。
如果是重要内容:
You can request persistent storage for your site to protect critical user or application data.
persistent storage:除非是使用者自行清除,不然是能够避免浏览器的自动清除。
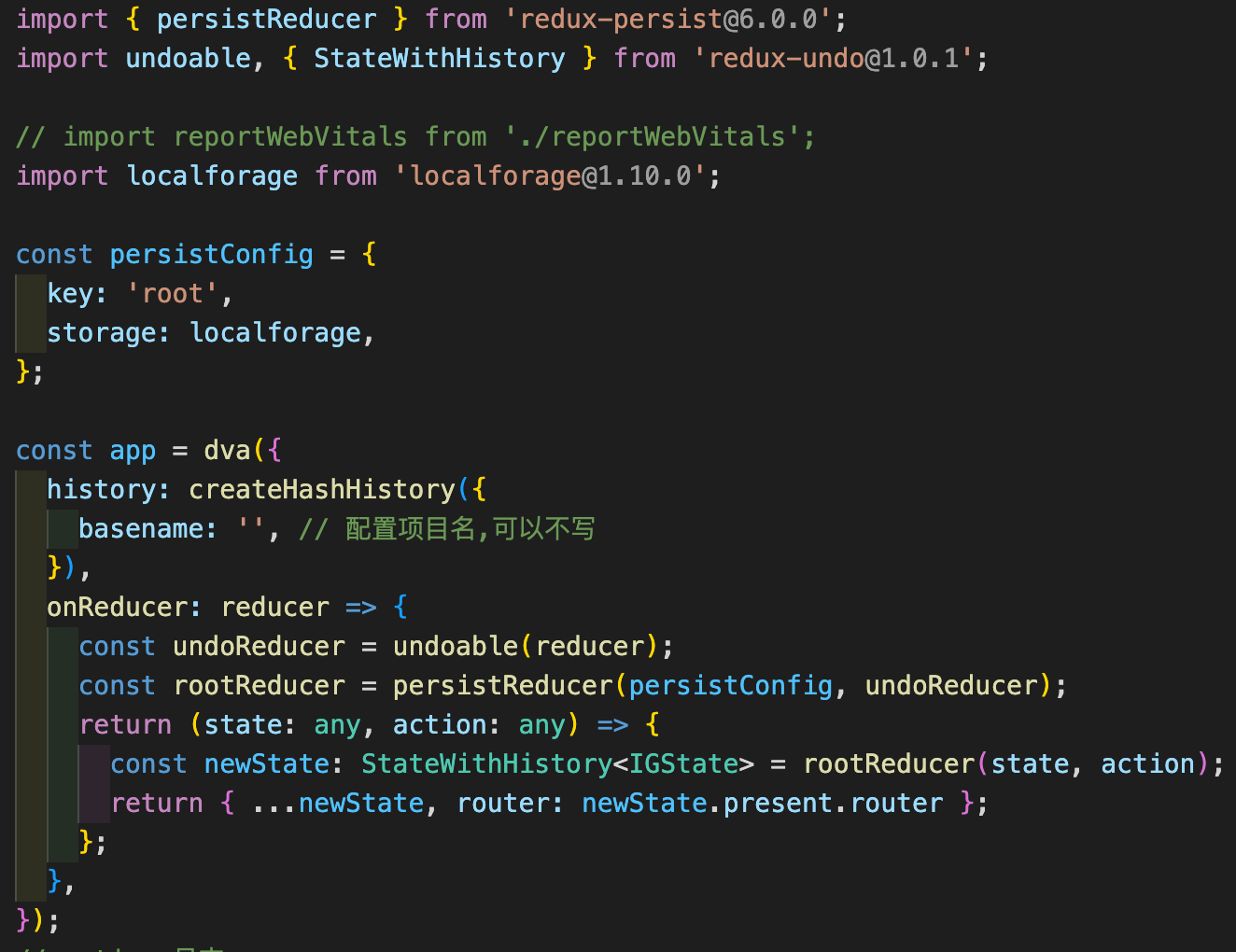
Redux Persist:Persist and rehydrate a redux store.
- 本文链接:http://example.com/2021/03/01/browser/indexdb/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。